И снова здравствуйте!
Как оказалось, День Знаний на самом деле сегодня, поэтому продолжаем разговор.
Отложим практику и займёмся теорией и немного философией.
Поговорим про оптимизацию приложений. А так как преждевременная оптимизация — смертный грех, то про оптимизацию нагруженных приложений.
Не будем лезть в подробности, а просто попробуем разобраться в каких местах вообще следует оптимизировать.
Также затронем вопрос, а могут ли интерпретируемые динамические языки (в первую очередь наш PHP) с их невысоким быстродействием использоваться для построения высоконагруженных систем.
Легендарный срач
Сначала вспомним особо клинический случай: частые споры на счёт того, что следует использовать для большей эффективности: echo или print, for или while, и вообще имеет ли право на жизнь ООП, если обычные функции работают чуточку быстрее.
На что следует вполне резонный ответ:
— время исполнения конструкций языка ничтожно по сравнению со многими другими процессами и любой SQL-запрос перекроет всю вашу оптимизацию на порядок.
А на него следует контр-аргумент:
— когда ваше приложение станет по настоящему высоконагруженным могут сказаться любые микросекунды.
С первого взгляда это утверждение кажется обоснованным. Но если разобраться, то оказывается в нагруженных системах эти оптимизации даже ещё менее значимы, чем для простого говносайта на обычном говнохостинге.
Люди против железяки

Как многие, наверно, догадываются, высоконагруженные приложения не работают на виртуальном говнохостинге. И у их владельцев обычно есть деньги, как на оплату дорогих программистов, так и на оплату всяких железяк.
Итак, проблема: ваше приложение стало притормаживать. Есть два варианта решения:
1. Взять трёх программистов с з/п=100 т.р, оторвать их от развития вашей системы и заставить месяц всё это оптимизировать.
2. Купить железа на, допустим, 30 т.р.
Обычно, всё-таки выбирают 2-е.
Вкладывать деньги в железо можно двумя способами:
1. Набить в одну тачку побольше памяти, покруче процессор, побольше диск и ещё красивенькие синенькие лампочки, чтобы мигали.
2. Купить несколько машин, попроще, но побольше. А потом докупать ещё.
В 1-м случае, какой-бы не была прокаченной тачкой, она всегда достигнет предела. Причём, обычно, очень скоро.
Поэтому единственный правильный путь тут — побольше машинок, хороших и разных.
Однако, это ни разу не означает, что всё решается одним железом, а разработчики могут просто получать свои 100 т.р. и ни о чём не париться. Париться они должны по полной программе, только совершенно о других вещах.
Масштабируемость
И первая вещь — масштабируемость. Некоторые считают, что масштабируемость, это тоже самое, что оптимизация, эффективность и т.п. А это не так.

Пример: есть у меня технический блог, на который заходят десяток моих знакомых и который лежит на дохленьком сервачке и прекрасно себя чувствует.
И вот я решил ввести рубрику «Субботние сиськи»! В течении месяца количество уникальных пользователей в день достигло ста тысяч миллионов. И явно, какой бы у меня не был эффективный и оптимизированный блог, сервер просто не выдерживает этого.
И тут два варианта:
1. Если моя программная часть масштабируемая: я повесил на сайте рекламу, получил миллиард долларов и купил на него тысячу серверов, да ещё и на пиво осталось. Мой сайт продолжает работать, популярность повышается, а я только докупаю сервера. Вернее кто-то другой докупает, а я на Гаваях на пляже лежу.
2. Не масштабируется: сайт умер, люди ушли, я потерял свой шанс и стал алкоголиком.
То есть масштабируемость, это возможность отвечать на возрастание нагрузки простым расширением аппаратной части. Причём действия при этом простейшие и выполняются системным администратором. Ни программистов, ни код при этом никто не трогает.
И тут оказывается, что просто так масштабируется далеко не всё. И просто куча железа сама по себе ничего не стоит.
Не масштабируемые компоненты
РСУБД

Например, MySQL сам по себе ни разу не масштабируется.
То есть вы сделали всё отлично в соответствии с реляционной теорией: нормализованные таблицы, связи, запросы с JOIN’ами, по полному использующие реляционную модель. И радуетесь, что всё так красиво.
А потом сто тыщь миллионов пришли к вам посмотреть на сиськи. Таблицы забились тоннами данных, которые уже не влезают даже в 64 Гб оперативки, даже ФС уже не справляется, куча параллельных запросов ждёт снятия блокировок с нужных таблиц, а индексы вообще перестраиваться не успевают. Ад кромешный.
Итого, нам не хватает ни объёма, ни быстродействия.
Тут у нас есть, конечно, репликация. Но она решает только проблемы с быстродействием. И то только до некоторого уровня. Поставьте серверов десять и их синхронизация убьёт всякую выгоду от распределения запросов. По поводу объёма репликация вообще ничем не поможет.
Таким образом от того, что рядом с MySQL-сервером мы просто поставим ещё один, ничего не случится.
Поэтому поверх MySQL уже программными средствами приходится строить свою масштабируемую систему. Например, с использованием шардинга.
Key-value
key-value (Memcached, Redis и т.д) хранилища масштабируются намного проще. Распределяем с помощью какого-нибудь хэша ключи по серверам и радуемся.
Но тут тоже есть свои нюансы:
- Хэширование ключей нужно реализовывать в коде, то есть сразу предполагать, что у нас будет масштабируемая система
- Даже консистентный хэш не позволяет добавлять новые сервера совершенно без потерь данных, для постоянного хранилища это может привести к проблемам
- Key-Value масштабируемы сами по себе до тех пор, пока они, собственно, Key-Value, то есть запрос идёт по конкретному ключу. Можно и MySQL сделать key-value хранилищем и он так же будет масштабируемым. Если же мы начинаем, к примеру, вычислять перечисление множеств в Redis’е, то изначальная масштабируемость рушится (на каких там серверах у нас эти множества?). Приходить опять поверх хранилища писать свою масштабируемую систему.
- Ну и не готовы пока key-value базы полностью заменить реляционные.
PHP — масштабируемый
А пых — масштабируемый. И совершенно без проблем.
Есть у нас сервер с кодом, который перестал справляться с нагрузками: ставим сто серверов, переносим на все из них этот код, ставим балансировщик и все запросы равномерно распределяются между вычислительными мощностями этих ста машин. Через время добавим ещё сотню.
Все эти манипуляции делаются сугубо системным администратором и никак не затрагивают код.
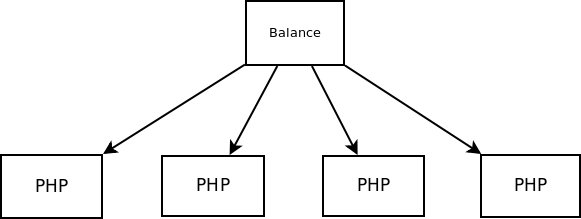
Это похоже на репликацию MySQL, за двумя исключениями:
1. Проблема с объёмом не стоит: даже Лев Толстой не напишет столько кода, который бы не поместился в оперативку.
2. Проблема с синхронизацией тоже ничтожна. Если в базе данные могут изменяться сотню раз в секунду, то код на рабочую систему будет заливаться максимум раз в сутки, когда-нибудь ночью.
Вывод: оптимизация вычислений внутри сценария PHP (и любого другого языка в данном случае) последняя оптимизация, которую нужно делать.
Это не значит, что нужно писать полное гуано, а так же запрещается ставить акселераторы и переписывать некоторые часть на Си. Это значит, что не нужно парится над тем, над чем не нужно, тем более, что парится в крупной системе придётся ещё над многим.
PHP vs базы: блокировки данных
И ещё важное отличие процессов PHP (Python, Ruby, …) от хранилищ (реляционных, файловых, ключевых, …).
PHP-процесс не держит никого кроме пользователя за браузером (а тот простит ему лишнии 0,1 сек) или вообще никого (CRON-сценарий).
Ну разве что отъедает процессорное время от других процессов, но ведь он масштабируемый — это легко решается.
А вот любое хранилище может параллельно обрабатывать запросы от множества PHP-сценариев. Выполнение одного запроса может блокировать сотню ожидающих.
«Пусть каждый делает свою работу. Например, обработкой данных занимаются базы данных.» — это утверждение верно для не сильно нагруженных приложений. А для нагруженных верно уже с оговорками.
Изолированному PHP-сценарию мы можем простить некоторую медлительность, а вот базе, обслуживающей уйму запросов не можем.
Поэтому каждый сценарий, прежде чем посылать куда-то запрос должен трижды подумать, по максимуму подготовится к этому, а потом быстренько спросить что-нибудь у базы и отвалить.
Пример
Есть сценарий, запускающийся по CRON’у раз в час и выполняющий какие-то действия в базе: пересчёт чего-нибудь, ведение статистики, сборка мусора, всё равно чего.
Есть два варианта выполнения:
- Извлечь данные из MySQL (0,05 cек), обработать их в PHP (10 мин) и сохранить результаты (0,05 сек).
- Выполнить всё на стороне MySQL (сложный запрос или хранимая процедура) — 10 сек.
Итак, 10 минут против 10 секунд. Обычно, это яркая иллюстрация того, что каждый должен делать свою работу. Пусть база данных делает то, для чего предназначена — обрабатывает свои данные.
Но есть и другие числа — 0,1 секунды против 10 секунд. Это время на которое мы грузим БД.
То есть у нас с одной стороны база данных, которой приходится напрягаться на протяжении 10 секунд со сложными вычислениями, в то время, когда у неё кроме них ещё тысяча параллельных запросов.
А с другой — PHP-сценарий, который чухает где-то на своём сервачке в фоновом режиме и никого не беспокоит. 10 минут поработал, 50 минут постоял.
Как видно обработка данных на PHP в некоторых случаях может быть эффективнее, чем в БД :)
Пример с CRON’ом несколько утрирован, но в принципе он подходит и для обычных сценариев. Лучше заставить пользователя подождать ответа лишние 0,1 секунду, чем загрузить базу.
Выводы
Теперь попробуем сформулировать общие выводы.
Главное — архитектура
В крупной системе главное на сценарии на языке программирования и даже не структура базы данных. Главное, это то, как они все связаны и какие интерфейсы друг другу предоставляют. Какие данные кто хранит и как их обрабатывает. То есть архитектура.
Именно над архитектурой и стоит ломать голову в первую очередь.
Архитектура компонентов
После общей архитектуры важна архитектура входящих в неё компонентов. Структура баз данных, программные алгоритмы и т.п.
Как мы видели выше, архитектура программной части здесь на последнем месте. Не значит, что она не существенна, а значит, что другие более существенны.
Здесь важно понимать, что относится к архитектуре программной части:
Когда мы в PHP-библиотеках реализуем систему шардинга для MySQL, это относится больше к архитектуре базы.
Когда мы выбираем отправлять ли из сценария сложный SQL-запрос или несколько простых, то это опять ближе к архитектуре базы и связей с ней.
А вот иерархия объектов в сценарии, а так же замена всех print на echo, это уже к программной архитектуре.
PHP — прослойка
Итак, сложная система состоит из множества различных компонентов. А PHP всего лишь прослойка, обеспечивающая их взаимодействие.
Не стоит относится к этому, как к принижению нашего любимого пыха.
Во-первых, прослойка это не менее важный компонент, чем все остальные.
Во-вторых, любой другой язык программирования играл бы здесь точно такую же роль.
И ответ на на озвученный вопрос «может ли язык с не слишком высокой производительностью быть использован в высоконагруженных системах».
— Да, может. Может, нах! За счёт высокой масштабируемости программной части, язык следует выбирать исходя из достаточной его выразительности для вас, а не из потребляемых тактов процессора.
Не всё так просто
На высоконагруженных системах некоторые заученные правила неожиданно переворачиваются.
Строгая реляционная модель даёт трещину, мощные запросы начинают проигрывать простым, БД временами становится не лучшим местом для обработки данных, а оптимизация программной части становится ещё менее нужной, чем для слабонагруженных систем.
Говна не делать!
Всё, что сказано про оптимизацию, не означает, что нужно писать дерьмовый код (железо всё стерпит). Не означает, что если у руководства есть деньги, то пусть тратит их побольше на железо. Не означает, что нельза написать такого кода, когда никакое масштабирование не поможет.
Просто мало-мальски опытный программист не напишет кода, который будет уж вообще неэффективным. А после этого пусть думает не над дальнейшей оптимизацией конструкций, а над более интересными вещами.
Тью. Я думал, что при использовании репликации можно бесконечно увеличивать кол-во серверов с БД и все будет клево. А оно вот как оказывается…
Абырвалг, 1.09.2010, 16:34
Статья хорошая в своем роде, но для некоторых читателей, автор(однофамилец) не открыл чего то нового. Это все давно написано в заумных книгах, причем заумно :) Так что спасибо что осветил некоторые аспекты теории высоких нагрузок и борьбы с ними понятным языком!
IvanSCM, 1.09.2010, 16:37
Абырвалг, Смотря какое у тебя отношение выборок к изменениям.
Если read-only база, то можно бесконечно.
vasa_c, 1.09.2010, 16:38
IvanSCM, ну я на вселенские откровения и не претендовал :)
Просто, когда начнут на форуме про echo vs print тереть будет на что кинуть ссылку
vasa_c, 1.09.2010, 16:40
думаю будет «в тему» http://www.slideshare.net/Slach/phpconf-2010
Абырвалг, 1.09.2010, 16:42
Круто. Круто нах!
kostyl, 1.09.2010, 17:08
все логично, почитал — поржал. люблю такой стиль, го зачод как всегда))
phpdude, 1.09.2010, 18:56
Теорему Брюера знаешь?
Она как раз хорошо описывает проблему маштабирования:
«В распределённой системе невозможно обеспечить одновременное выполнение всех трёх условий: корректности, доступности, устойчивости к сбоям узлов.»
http://softwaremaniacs.org/blog/2010/01/31/brewers-cap-theorem/
Горбунов Олег, 1.09.2010, 19:26
Ага, выберите любые два :)
vasa_c, 1.09.2010, 21:07
>Ага, выберите любые два :)
А, ну там как раз об этом :)
vasa_c, 1.09.2010, 21:09
А раздел про сиськи у тебя будет? =DDD
Sinkler, 1.09.2010, 22:27
Как только сделаю масштабируемый вордпресс, сразу добавлю к нему плагин с сиськами.
vasa_c, 1.09.2010, 23:23
Здорово. Я даже и не представлял, что могут возникнуть такие проблемы…
Как то само сабой получалось…
Правда я поборник и фанат микрооптимизаций, но факт есть факт. Оно зараза работает, и начальство довольно))
twin, 2.09.2010, 1:04
Начну свой коммент, как всегда, с аксиомы, что ГО охуенен.
А теперь пара вопросов:
> То есть вы сделали всё отлично в соответствии с реляционной теорией: нормализованные таблицы,
> связи, запросы с JOIN’ами, по полному использующие реляционную модель. И радуетесь, что всё так
> красиво.
Я всегда думал что в высоконагруженных системах рулит денормализация в некоторых пределах(т.е. где-то храним данные нормализованными, но бегаем с выборками исключительно по денормализованному «кэшу»)
Я не прав?
>Тут у нас есть, конечно, репликация. Но она решает только проблемы с быстродействием. И то только до
>некоторого уровня. Поставьте серверов десять и их синхронизация убьёт всякую выгоду от распределения
>запросов. По поводу объёма репликация вообще ничем не поможет.
Слушай, а это на каком примерно уровне высоконагруженности работает?
Ну т.е. вот есть у нас сферическое приложение в вакууме соотношением чтение/запись в 50/1 (Какая-то запись, девять комментов, 500 просмотров). Ставим, скажем, 3 крутых мастера, 150 детей и вполне себе хорошо живем. При какой нагрузке это перестанет работать? сто тысяч? сто пицот? миллион?
Т.е. стоит ли всерьез задумываться на начальном этапе?
dallone, 2.09.2010, 9:40
twin, да, знаем мы вас с ваше микрооптимизацией :)
vasa_c, 2.09.2010, 11:01
dallone,
>Я не прав?
Прав. Там как раз про то, что радоваться было рано.
vasa_c, 2.09.2010, 11:01
dallone,
>репликация.
А ставить сразу 150 шт, имхо, бессмысленно.
При низкой нагрузке задействованы параллельно на выборку будут только несколько серверов, а вот вставки будут гонять трафик по всем.
Точная цифра потолка зависит от соотношения чтения/записи и ещё кучи всего. Я её так просто сказать не могу, знаю только что она далеко не бесконечна.
Лучше у Психа на php.ru спросить.
vasa_c, 2.09.2010, 11:07
Ясно, спасибо.
Просто я в раздумьях, когда пора будет осваивать key-value хранилища, поэтому хотел узнать до какого предела я смогу выезжать на реляционной БД.
dallone, 2.09.2010, 14:49
Освой их привентивно :)
Они заслуживают внимание не только, как замена реляционной.
vasa_c, 2.09.2010, 17:15
key-value и не могут быть заменой реляционных, это глупо. На задачах, где много однотипных данных без сложной иерархии реляционные будут в десятки раз быстрее иерархических БД, и наоборот. И вот как раз умение разделить эти задачи — и есть ключ к успеху.
Горбунов Олег, 2.09.2010, 18:06
Не знаю, причём тут иерархия и, скажем, мемкэш, но, да — каждому своё.
vasa_c, 2.09.2010, 18:17
>И ответ на на
на-на
adw0rd, 6.09.2010, 11:58
интересный вариант- обработка данных на ПХП ) Хоть бери и ускоритель ставь. Вообще-то в таком случаи пишется на С++ программка которая обрабатывает данные. Если поток данных велик- то обработка идет на машине с толстыми каналами до СУБД.
CoolerDAO, 3.10.2010, 2:38
Извините накипело.
«GOпник, он всегда гопник.»
На чём писать прослойку в действительности практически не важно. Большинство и среди них гопники, не задумываются о том, что код который они пишут будет поддерживаться не ими. И вот такие гопники будут доказывать, что не важно, что код написан жопой и все можно исправить железом. А то что развивать их код будет не железо, а такие же дорогостоящие программисты им в голову не приходит. Самоутверждающиеся гопники могут насрать такой ажурный-объектный-говнокодом, что для того чтобы создать раздел «Субботние сиськи» уйдёт года два и никакое количество железа в этом не поможет.
Уметь программировать это не значит знать набор команд в каком-то языке или фреймворке, это скорее умение проектировать легко развиваемые системы. Что бы было понятнее: «Гроссмейстер не то кто знает как ходят шахматные фигуры, а тот кто смотрит на много шагов вперед».
legion, 6.11.2010, 23:43
legion, не особо понятно вы за кого в вашей истори- за гопником или за дорогостоящих программистов, которые не могут сделать раздел с сиськами за два года, судя по повествованию именно к гопникам, спасибо большое, что рассказали идеологию гопников от первого лица!
phpdude, 7.11.2010, 12:42
legion, спасибо за ваш отзыв.
К сожалению, я мало в нём понял.
Вы этим говорите типа «+1» или наоборот утверждаете, что PHP — говноязык и никакие дорогостоящие программисты не смогут поддерживать систему на нём? :)
vasa_c, 7.11.2010, 12:42
Объясняю ещё раз «язык не причём». PHP достойный язык. Написать не развиваемую и не модифицируемую систему можно на чём угодно. И какой бы код не был масштабируемый, если его не сможет поддерживать посторонний человек, то это по определению говнокод. И как следствие потенциальная или реальная масштабируемость будет представлять нулевую ценность. Можно написать функциональным стилем очень прозрачную систему, а можно и объектами нагородить огород. +1 Что архитектура это главное, только вот архитектура должна быть не только высокопроизводительной и масштабируемой, но и гибкой для изменений и простой для её поддержки. Простота изменения может сделать не масштабируемую систему масштабируемой, а непроизводительную производительной. Возвращаясь к аналогии с шахматами, если вам через три хода мат, то совершенно не важно из чего сделаны фигуры из слоновой кости или пластика. Неважно на чём вы пишете, если для каждой новой задачи вам или кому-то другому придётся переписывать весь код заново. В таком случае можете даже не думать о производительности.
legion, 7.11.2010, 15:07
legion, и че? =D
Sinkler, 7.11.2010, 15:12
Я понял, то что legion то же самое говорит, что и ТС, только вот оба не полностью раскрывают высший смысл, а описывают вокруг да около..
kostyl, 7.11.2010, 15:17
Забавно было почитать, возможно многим в таком формате приятнее воспринимать информацию о Highload, чем то, как об этом пишу я :)
Есть над чем задуматься…
Иван Блинков, 2.05.2011, 1:19
Иван Блинков, спасибо. Приятно, что такие люди сюда заглядывают :)
vasa_c, 2.05.2011, 20:17
и таки да, воспринимать в таком виде проще. как то оно сказано легко и подано понятно. Я был на сайте уважаемого Блинкова… читал. вроде и слова понятные, и термины, которые не знаешь можно прогуглить. но быстро теряешь нить, потому что постоянно отвлекаешься на мысли о том что же это слово обозначает:) ну и простые, доступные, жизненные примеры это главное как по мне. Сразу становиться понятна суть, а детальнее про термин я потом в Вики почитаю. Ведь статьи эти не для профи, которые сами комухош расскажут, а, наверное для тех кто только пытается и дерзает:) в общем, наговорил я тут. спасибо:)
иван, 18.07.2012, 8:45
У нас тут тоже есть хайлоад проект, вот можете почитать про наши решения — http://plutov.by/post/tuffle_servers
Саша, 24.06.2014, 23:35